The technological advancements are increasing every day. Global manufacturers are emphasising the CPU and computing power to boost production efficiency. Thus, tech giants like NVIDIA, Intel, AMD, and others are booming and dominating the supply chain of CPU processors. Parallel computing and GPU usage are increasing drastically due to the intensive computational demands.
CUDA (Compute Unified Device Architecture) is a parallel computing platform and API developed by NVIDIA. Developers use CUDA to accelerate tasks like matrix multiplication.
Fact Box: Industries report 20 times speedups and 30% efficiency gains; learning CUDA is both practical and future-proof.
CUDA is utilized in machine learning, research, medical sciences, physics, supercomputing, mining, and more. Beginners will gain essential insights into CUDA, its functions, and its benefits in this blog. Continue reading.
Table Of Content
What is CUDA? Explained in a Nutshell
CUDA was first launched in 2007 by NVIDIA, though development began earlier, and the first version of the CUDA platform was released in 2006. It’s a parallel computing platform and programming model that allows developers to use a GPU dedicated server for general-purpose processing. It offers a powerful set of tools to offload computationally heavy tasks from the CPU to the GPU. CPUs/GPUs’ processing power increases along with the performance of several applications.
CUDA vs. CPU Cores
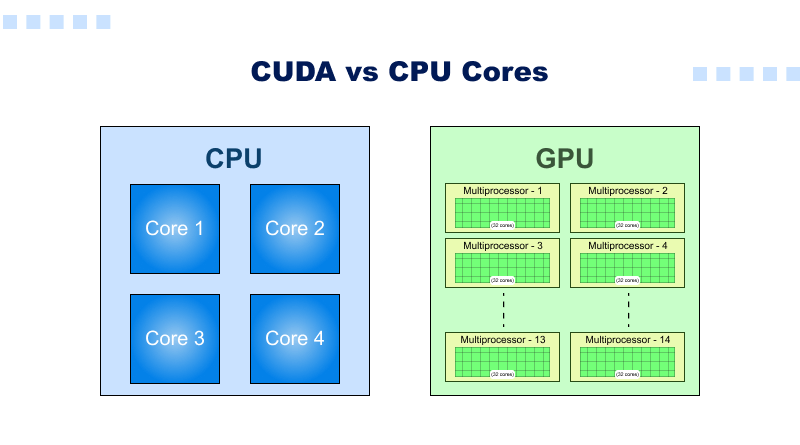
CUDA Cores: CUDA cores are integrated with NVIDIA GPUs and engineered for parallel and high-throughput calculations.
- CUDA cores achieve a rapid rate of single-precision floating-point (FP32) calculations.
- Streaming Multiprocessors (SMs) are the architectural blocks including thousands of CUDA cores
CPU Cores: CPU cores handle sequential, single-thread performance and are optimised for complex instructions with low latency, like our web hosting plans.
- Operations like complex calculations, memory fetching, and I/O are done by the CPU.
- A CPU typically has a smaller number of cores compared to a GPU’s CUDA cores (e.g., up to 48 cores on a high-end CPU).
The Evolution of CUDA
CUDA has covered a long journey since its inception. Here are some key milestones we are highlighting.
- 2006: The first version of CUDA came out, allowing developers to create applications that could leverage the power of GPUs.
- 2010: CUDA 3.0 came out, and it introduced dynamic parallelism, which allowed kernels to be able to spawn other kernels.
- 2020: CUDA 11 came out, which added numerous features and improvements geared toward machine learning and other AI applications.
Key Feature of CUDA
- CUDA is compatible with several different high-level programming languages, C, C++, and Fortran. Knowledgeable developers in one of these languages should be able to use CUDA with no issue.
- CUDA is set apart from other forms of programming because of the speed and parallelism that it brings to the table. Accelerated computing brings even greater speed improvements, especially in tasks in the deep learning realm, complex image processing, and even scientific computing.
- CUDA also provides other resource management capabilities, with being able to partition memory into smaller chunks, such as local and shared, and even some of the textures. This leads to even more improvements in performance.
How Do You Use CUDA?
CUDA relies on the installation of the NVIDIA CUDA Toolkit, as well as a few other specific drivers. Once you have that, you can create your CUDA program that should be able to contain a kernel function that performs parallel execution on the GPU. If you want to interleave the CPU and GPU with data, you will want to utilize the cudaMemcpy function. Here is the process in more detail.
Step 1: Installation and Setup
- Ensure your system is compatible with CUDA configurations by using nvidia-smi list GPUs.
- Install the latest drivers from NVIDIA’s website for the GPU.
- Download and install the CUDA Toolkit from the NVIDIA website.
- Install the CUDA installation directory into the PATH and configure the compiler’s
CUDA_HOMEenvironment variable so it can find it easily. - After the successful installation, run through some samples provided with the toolkit to test that everything is working properly.
Step 2: Write a CUDA Program
- Add CUDA headers.
- Write code that runs on GPU; ensure it includes the keyword “global” to indicate it as a kernel function.
- When allocating memory for your data in the CPU’s main function, allocate memory as per the available disk space.
- Transferring Data: Copy your inputs from the CPU host to the GPU device using
cudaMemcpyHostToDevice. - Calling the kernel function with the desired number of blocks and threads per block will determine your parallel execution grid. Copying back results using
cudaMemcpyDeviceToHostwill bring results back from the GPU to the host (CPU). - Use
cudaDeviceSynchronize()to wait until all tasks on the GPU have completed before proceeding with CPU tasks. - Free any allocated device memory.
Step 3: Compile and Run
- Use the CUDA Toolkit’s nvcc compiler to compile your .cu file—for instance, “
nvcc your_program.cu -o your_program.“ - Launch your compiled program directly from your terminal.
- To help troubleshoot and verify installation issues, try building and running the samples that are included with the toolkit to test for installation issues. This may help ensure proper functionality.
How Do Developers Use CUDA?
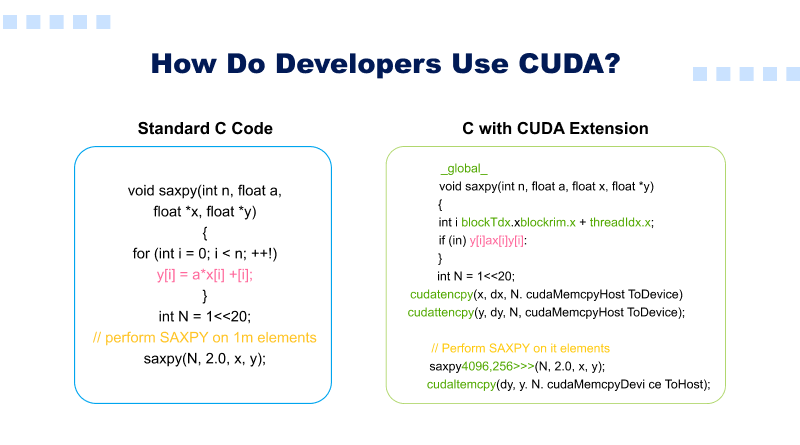
Developers write programs using an ever-expanding list of supported computer languages, including C, C++, Fortran, Python, and MATLAB with basic keyword extensions.
These keywords allow a developer to easily express massive parallelism and direct the compiler (or interpreter) toward those sections of an application that use GPU accelerators.
This simple illustration explains how a standard C program can be accelerated using CUDA.
CUDA Alternatives
CUDA vs OpenCL
| Feature | CUDA | OpenCL |
| Vendor Support | Proprietary to NVIDIA; designed exclusively to run on its GPUs. | An open standard maintained by Khronos Group that runs on GPUs, CPUs, and accelerators from different vendors (NVIDIA, AMD, Intel etc). |
| Portability | Low portability; dependent upon NVIDIA hardware. | High portability; designed with “write once, run anywhere” fundamental across compliant hardware platforms. |
| Performance | NVIDIA hardware runs faster because it uses special built-in libraries (like cuDNN for deep learning and cuBLAS for math operations). | If you don’t use these libraries, you can still get similar speed by manually fine‑tuning your code, but it usually takes more time and effort. |
| Ecosystem & Libraries | CUDA offers a mature ecosystem, complete with high-performance libraries, development tools, and a thriving community. | OpenCL offers several libraries; however, its ecosystem tends to be less extensive due to lack of unified vendor tooling support. |
| Ease of Development | It is perceived as simpler to use and provides a smoother development workflow. | Required additional boilerplate code and manual optimization for various devices may be needed to attain high performance levels. |
Glossary: Boilerplate code are the reusable sections of code that are repeated with little or no alteration across a project to ensure consistency and efficiency.
NVIDIA CUDA vs AMD ROCm
| Feature | NVIDIA CUDA | AMD ROCm (Radeon Open Compute Platform) |
| Vendor & Model | NVIDIA (RTX, A-series, H-series etc.) | AMD (Radeon Instinct MI-Series) |
| Licensing | Provide proprietary solutions with tight vendor lock-in. | Open source offerings foster community participation and greater flexibility. |
| Maturity & Ecosystem | Highly Mature (Launched 2007). An industry standard with unparalleled library optimization (cuDNN, cuBLAS). | Growing Rapidly (Launched 2016). Improving libraries (MIOpen, rocBLAS) but still playing catch-up. |
| Code Portability | Low. Need necessary rewriting for other platforms. | High via HIP (Heterogeneous-Compute Interface for Portability), a C++ layer that facilitates easy “hipify” conversion of CUDA code. |
| Low-Level Dev | C/C++ with CUDA Kernels is the primary approach, offering optimized access to NVIDIA Tensor Cores directly and efficiently. | An open-source stack allows deeper inspection and customization at every layer of the system. |
Writing Your First CUDA Program
To understand the basic structure of CUDA, we share the programming steps of “Hello World.” Here is the code syntax.
#include <stdio.h>
global void helloWorld() {
printf("Hello, World from CUDA!\n");
}
int main() {
helloWorld<<<1, 1>>>();
cudaDeviceSynchronize();
return 0;
}Compiling and Running CUDA Programs
Follow these steps to compile and run CUDA programs:
Open the command prompt/terminal. Navigate to where your file resides before compiling with this command:
nvcc -o hello hello.cuRun the program with:
./helloArchitecture of CUDA
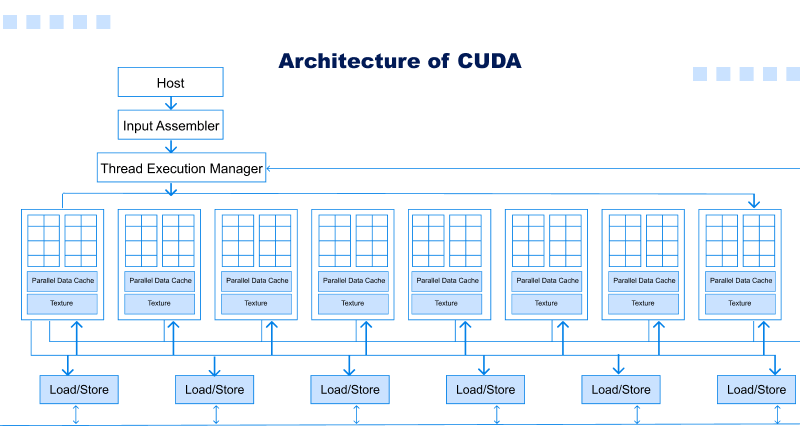
- In the above diagram, 16 Streaming Multiprocessor (SM) diagrams are presented. Each SM has 8 Streaming Processors (SPs), giving us a total of 128 SPs.
- Now, each streaming processor includes both a MAD unit (Multiplication and Addition Unit) and an additional MU (Multiplication Unit).
- The GT200 features 30 Streaming Multiprocessors (SMs), each equipped with eight Streaming Processors (SPs), providing over one TFLOP of processing power.
- Each streaming processor can run multiple threads efficiently and can support thousands of them per application. On the G80 card, there are 16 Streaming Multiprocessors (SMs), and each SM has 8 Streaming Processors (SPs). Thus, there are 128 SPs total with 768 threads supported per SM (not per SP).
- At last, each Streaming Multiprocessor had eight SPs; each SP could accommodate a maximum of 768/8 = 96 threads at one time. Therefore, each SP can run 12,228 times on 128 SPs—hence these processors are considered massively parallel. G80 chips had an 86.4 GB/s memory bandwidth.
- It has a dual 8 GB/s communication channel with its CPU: four for uploading content directly into RAM and four for downloading from it.
Typical CUDA Program Flow
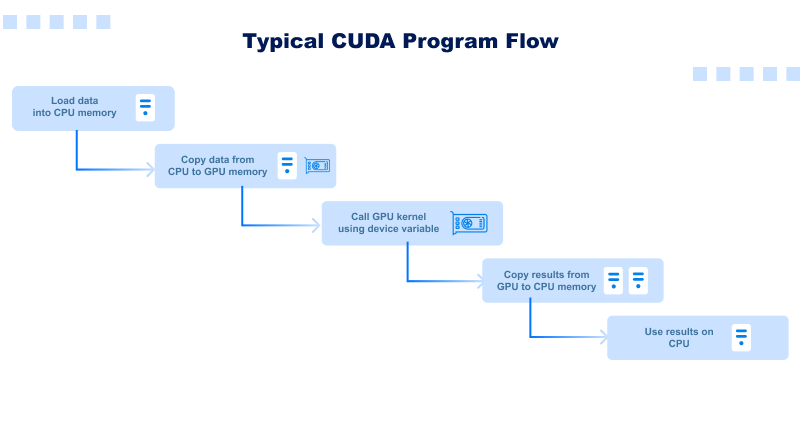
- Load data into CPU memory.
- Copy data from CPU to GPU memory—e.g., cudaMemcpy(…, cudaMemcpyHostToDevice).
- Call GPU kernel using device variable—e.g., kernel<<<>>>. (gpuVar)
- Copy results from GPU to CPU memory—e.g., cudaMemcpy(.., cudaMemcpyDeviceToHost).
- Use the results on the CPU.
Benefits of CUDA
1. Performance and Speed
With CUDA, you can execute thousands of threads on the GPU at the same time. This brings down the time taken as compared to executing the threads on the CPU. This accelerates the training of deep learning models and shortens the time taken to complete the workload. In addition, it supports inference in real-time with low latency.
2. Developer and Ecosystem
NVIDIA provides extensive CUDA libraries such as cuDNN and TensorRT. This library-rich ecosystem is then wrapped around the most commonly used programming languages like C, C++, and Fortran. TensorFlow and PyTorch have been customized and optimized for CUDA for GPU acceleration.
3. Resource Management
CUDA improves the performance and resource allocation by its sophisticated management of different kinds of memory such as local, shared, and global memories. Unified memory prefetching is one of the features that enhance performance by improving memory access management.
Writer’s View
With the advent of AI/ML applications, the usage of GPU-dedicated servers will increase. NVIDIA’s CUDA performs multiple complex tasks like scientific simulations, AI, and data processing faster. CUDA allows developers to write code in familiar languages like C, C++, or Python to run across thousands of GPU cores simultaneously.
Newcomers can grasp the basics of GPU architecture and kernel functions, and then they can start experimenting on heavy-duty operations like matrix multiplications, deep learning, or image recognition.
The Bottom Line
CUDA power is beyond graphic processing. NVIDIA has predicted the demand for upcoming supercomputing and mission-critical applications and introduced CUDA. CUDA enables programs to run across thousands of GPU cores. It facilitates the functionality of heavy workloads like artificial intelligence, scientific simulations, and big data analysis.
For beginners, imagine CUDA is a toolbox that turns your GPU into a general-purpose computing platform. You write the code in common languages like C, C++, or Python, and CUDA handles splitting the work into many threads. Faster performance and problem-solving ability make it a better choice than a CPU. In a nutshell, if you don’t have building access to a supercomputer, then CUDA is your gateway into high-performance computing.
FAQs
1. What is CUDA used for?
With the parallel processing power of NVIDIA GPUs, CUDA makes it possible to improve the performance of applications such as sci\-sim, video processing, and data analytics.
2. How does CUDA work?
CUDA creates a setting where developers can define a function known as ‘kernel’ which, upon being triggered by the CPU, distributes thousands of tiny threads to be executed across the GPU’s cores.
3. What programming languages support CUDA?
CUDA’s main languages are C, C++, and Fortran, whilst also being generally supported by other high-level programming languages such as Python and Julia via wrappers and libraries.
4. Why is CUDA important in AI and ML?
CUDA’s high degree of parallelism makes it possible to perform matrix multiplications and tensor calculations quickly, which are crucial in the training and inference of large neural networks, and is the reason it is a key driver in A.I/ML.